

Introducing the Data Powerhouse
‘A hybrid Modern Data Platform with Power BI’
William Rathbone – Data Analytics Practice Manager Simpson Associates
During my time in the Data and Analytics space (a couple of decades so far) there has been significant change. Most notable has been the democratisation of Data Analytics, or put another way, the ability for many more organisations to benefit from the insight that can be derived from the data that already flows around their organisation. In my view, this has occurred most significantly because of the reduction of a couple of keys barriers to entry; Cost and Complexity.
These two imposters arguably go hand in hand. A decade ago, handling Big Data typically meant an organisation had to invest in a dedicated appliance such as Netezza, an IBM Mainframe or Microsoft’s Parallel Data Warehouse; an investment that typically cost hundreds of thousands of pounds. This presented a significant barrier to entry for all but the largest organisations.
These high cost ‘relational’ appliances were challenged by the academic and search engine community through the evolution of lower cost platforms that provided distributed compute environments over predominantly file based sources; enter the world of ‘Open Source’ Big Data; the likes of MapReduce, Scala, Hadoop and patterns to organise the files they interact with – aka the invention of the Data Lake and ultimately the Lakehouse.
The downside of Lakehouse is complexity. Whilst strides continue to be made in what is possible outside of a relational engine using SQL, there can be limitations and the very administration of these environments can also be a challenge. I am often surprised to attend talks and presentations (including at this year’s SQLBits) on the latest and greatest non-relational approach which reveals with great aplomb the creation of a SQL style language which supports only a fraction of the operations of decades old relational engines.
So, to reverse a much-posed question in the last decade ‘Is the Lakehouse dead’? The answer of course, like the past question ‘Is the Data Warehouse dead’? No – but use of both of these needs to continue to evolve. In my view the Lakehouse has its place especially for low-cost storage (and processing) of large volumes of data especially associated with unstructured and semi structured data (a good example of this style of data being that originating from IoT Sources), however the trend to push perfectly good relational data through the lake (typically from a line of business application) seems counter intuitive.
So how do we bring together some of the cost, capacity and simplicity of access benefits of the Lakehouse with the familiarity and ease of use of the relational Data Warehouse – enter the ‘Data Powerhouse’.
The idea behind the Data Powerhouse is to take the relevant parts of the Power Platform (specifically Power BI), Lakehouse and Warehouse and put them together. This ‘pick and mix’ approach is obviously facilitated by the low-cost availability of these technologies as Pay As You Go Cloud Services; we no longer have to decide between Lakehouse or Warehouse. This results in a conceptual architecture that looks like this (shout out to Mike Dobing from SQL of the North for the basic structure of this diagram):
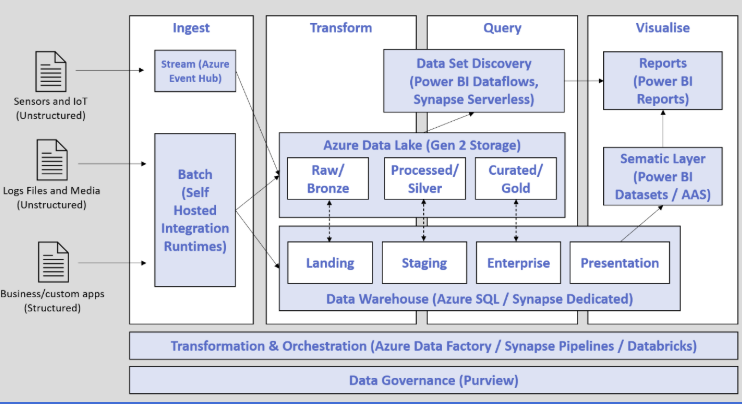
Figure 1 – The Data Powerhouse Architecture
The key aspects of note on this architecture are as follows:
- Data can be pushed either through the Lake or the Warehouse, with cross fertilisation possible (i.e. IoT Datasets once processed maybe Staging candidates within the Warehouse and anonymous datasets from Business/Custom Apps could be made available via the Lake from the Warehouse)
- End users are expected to predominantly access the Lake via Power BI Data Flows
- Early access to Processed Datasets is facilitated for Tactical / Operational reporting whilst the facility to fully model out to a Presentation layer and Power BI Datasets remains
- The Data Warehouse can be either Synapse or Azure SQL Server Based
I would very much welcome feedback from the community around this Data Architecture, what’s been missed, how could it be improved?
I have thought about one interesting future opportunity; the current assumption is that the Data Lake would need to be maintained by an ELT tool such as Azure Data Factory (including use of its Spark based Dataflows etc.). However, with Power BI Data Flows’ ability to write to the Data Lake and Power Query’s ability to transform Data, could we see the possibility of using Power Query as a possible Processing Engine for the Powerhouse?
For this to be viable, Dataflows need to write data in a Common Data Model format that is supported by other tools and support parquet (and delta?) but hopefully those capabilities are not too far off…..
Ref https://www.jamesserra.com/archive/2017/12/is-the-traditional-data-warehouse-dead/
Ref https://sqlofthenorth.blog/2022/03/10/building-the-lakehouse-architecture-with-synapse-analytics/


- Share
